前言
在nginx中,有两个常用的限速模块 limit_conn 与limit_req,他们两者使用的场景各异,下面试图从源码视角来分析这两个模块的实现。这两个限速模块是典型的使用共享内存的模块,在分析这两个模块的过程中,顺便可以学习nginx是如何使用共享内存。
1 实现方式
两个模块都是在preaccess阶段插入的handler钩子,每个请求来时都会经过handler处理一遍。
1 | limit_req |
2 配置解析
首先是共享内存的定义,由于两个模块都在配置上都相似,下面以limit_req的配置为切入点,观察配置与源码的关系
1 | limit_req_zone $binaray_remote_addr zone=one:10m rate=10r/s; |
这一行定义了一块共享内存,其中key为ip地址(一般key都为变量方式),大小为10m,名称为one,在limit_req场景下限速为每秒允许10个key。注意这写属性都是共享内存的属性,与location以及请求都没有关系。
关键成员解析:
1 | ctx = ngx_pcalloc(cf->pool, sizeof(ngx_http_limit_req_ctx_t)); |
这里将变量的index存放在ctx上: ctx->index = ngx_http_get_variable_index(cf, &value[i]);
nginx中常见这种写法:如果需要使用某个变量,则将该变量的index存放在结构体中,但这里需要注意的是,ctx这个名称一般都是与请求粒度相关的,请求销毁了,ctx也将销毁,但这里将ctx存放在了全局空间,申请在ctx=palloc(cf->pool,xxx)上, 这似乎不太符合命名规范。个人认为最好取名为zone_ctx, 即共享内存的上下文属性。
另外,由于这些成员没有存放在xlcf等location相关的结构体中,在后续使用的时候如何找到这里的ctx呢?答案是通过共享内存shm。由于ctx是和某个shm强相关,理所当然需要和相应的shm bind在一起。
1 | shm_zone = ngx_shared_memory_add(cf, &name, size, |
这里shm_zone的data将其联系在一起。那么问题是,如果找到某个指定的shm?是通过共享内存的名称即可。ngx_shared_memory_add(cf, &name, 0, &ngx_http_limit_req_module)即可找到相应的shm。
而后续如果要使用shm,那么肯定需要提供name来找到,这样就将各个变量的衔接打通了。
3 shm初始化与使用
上面只是定义了shm的各个属性,没有具体将shm初始化以及组织,而初始化由各个使用模块自定义。下面以limit_req模块对shm的初始化为例进行分析:
初始化的钩子是ngx_http_limit_req_init_zone
整个初始化的过程实际体现在如何给相关ctx赋值(前面提到的zone_ctx),来具体看下ctx的结构体:
1 | typedef struct { |
在申请shm的时候,rate、index、var等值已经被赋值过了,这里shpool是通过slab机制来使用shm的内存空间,是框架相关的机制,可以暂时不用关心(只需要知道使用slab机制可以高效地使用shm),后续对shm的内存分配都是通过ctx->shpool,不会直接在shm中分配,比如
1 | ctx->sh = ngx_slab_alloc(ctx->shpool, sizeof(ngx_http_limit_req_shctx_t)); |
那么具体的组织细节体现在对sh的赋值上,这也是每片内存所独有的组织方式,看下sh的结构体:
1 | ypedef struct { |
基本上将该片shm是通过红黑树和队列的方式组织的:
1 | ngx_rbtree_init(&ctx->sh->rbtree, &ctx->sh->sentinel, |
这里多说一下,在limit_conn中,只有rbtree的方式,后面会分析到在limit_conn场景中,只有快速插入、查找的需求,而在limit_req中,多了queue的组织方式,这里的queue是用来做lrucache,为了避免内存溢出,将访问时间近的节点插入队头。
在初始化shm的时候还有一个地方值得注意ctx->shpool->data = ctx->sh;
为啥要有这样的操作:主要是为了判断是否已经初始化这片shm,防止二次初始化,和业务逻辑没有关系,是shm框架使用。
- 使用shm
shm初始化完毕后,将通过location级别的指令指定使用那块shm,看下配置:1
limit_zone=one burst=5 nodelya
通过名称指定使用哪块内存,将其保存在lcf结构中,这是location级别相关的存储结构体
1 | typedef struct { |
其中shm_zone指向shm,burst和nodelay直接解析指令可以得到。
1 | lrcf->shm_zone = ngx_shared_memory_add(cf, &s, 0, |
即通过名称找到先前初始化ok的shm。
小结:以上是配置解析过程,总的来说就是将shm初始化完毕,然后通过name找到将要使用的shm联系起来。从中可以学习到shm的一般使用流程。
4 算法流程
下面是每个请求流过handler时候的逻辑,也是限流算法的核心:针对每个请求级别生效。对于limit_conn来说比较简单,先分析其handler: ngx_http_limit_zone_handler
- limit_conn
1 首先判断,这个r进入的location是否有定义限速:
1 | lccf = ngx_http_get_module_loc_conf(r, ngx_http_limit_conn_module); |
若该location没有设定限速,则直接跳过。(若设置了限速,lccf->shm_zone的值会指向某块内存,前面已述。
2 取出请求上变量值、查找vv = ngx_http_get_indexed_variable(r, ctx->index);
根据值在rbtree上进行查找:
1 | while (node != sentinel) { |
逻辑也是十分直接:若rbtree中有相应节点,判断节点的lr->conn是否超过设定location的lzcf->conn值,若没有超过,则增加该key的lr->conn值,然后直接放过,若超过了,则直接503掉。
至于放过后的请求,需要做收尾处理:当请求处理完成后,需要将lr->conn的值恢复,cleanup适合做这件事情:
1 | cln = ngx_pool_cleanup_add(r->pool, sizeof(ngx_http_limit_zone_cleanup_t)); |
将相应节点的conn恢复,若发现为0了,则将相应节点从rbtree中摘掉。
cleanup机制在nginx中使用十分场景,它提供了相当优雅的价值,为结束请求收尾处理提供了便利。
回到上面,如果没有在rbtree中找到相应key,则申请节点空间后插入rbtree,并初始化相应节点。
1 | n = offsetof(ngx_rbtree_node_t, color) |
- 小结:limit_conn的算法就是这样,从代码中分析可以看出,limit_conn的限速是一个存量的限速状态。
limit_req
下面分析稍微复杂一些的limit_req限速:其算法和典型的漏桶算法限速有些类似。在此之前先了解下什么是漏桶算法:
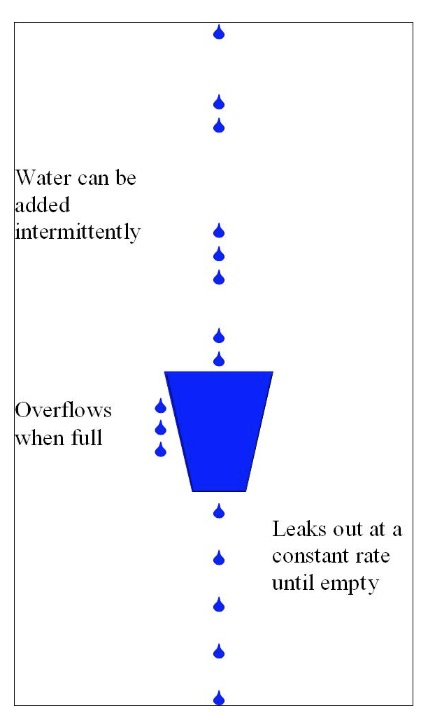
一个形象的解释是
- 水(请求)从上方倒入水桶,从水桶下方流出(被处理);
- 来不及流出的水存在水桶中(缓冲),以固定速率流出;
- 水桶满后水溢出(丢弃)。
这个算法的核心是:缓存请求、均匀处理、多余请求直接丢弃。
有了对算法形象的理解,再结合代码看nginx是如何实现该算法。
1 和limit_conn类似,首先判断该location是否开启了limit_req
1 | lrcf = ngx_http_get_module_loc_conf(r, ngx_http_limit_req_module); |
2 计算限速变量、查找
1 | rc = ngx_http_limit_req_lookup(lrcf, hash, vv->data, len, &excess); |
这里的返回值有几种情况:OK、BUSY、AGAIN、DECLINE
从简单的说起
DECLINE表示未查到相应节点,此时申请节点空间、初始化赋值后直接插入rbtree、queue
1 | if (rc == NGX_DECLINED) { |
逻辑很清晰:先申请空间,若空间不够,则从queue中进行lru淘汰一些节点(其实是直接从队尾删除,访问时间最久的点放在队尾)。 初始化节点,插入tree,插入queue首。直接返回,将请求交给下一个handler处理。
返回OK: 说明没有超过相应限速值,直接放过;
返回BUSY: 超过限速值,且漏桶容量不够,直接503掉;
返回AGAIN:超过限速值,但漏桶容量够,进一步看是否需要delay/delay处理,如果设置了nodelay,那么效果和返回OK一样,立即放行,如果没有设置,那么需要delay处理,nginx实现dealy处理的方法是,将该请求放入timer中,将该请求可写事件加入timer树。
如果结合漏桶算法的场景,这里的桶是指每个key都会有自己的桶。
回到lookup中去,漏桶算法的思想在其中:(截取)
1 | if (rc == 0) { |
如果查找到了相应key,先将其插入queue头,更新访问lr->last。漏洞算法的核心在这一行:
1 | excess = lr->excess - ctx->rate * ngx_abs(ms) / 1000 + 1000; |
其中lr->excess表示该key还剩多少请求未被处理,其更新方式为 : 上一次遗留 - 在此段时间已经处理的个数(如果按照限定的速度来估算)。
若遗留的数据以及超过了桶的大小(lrcf->burst),那么返回busy,将拒掉请求。
如果excess为0,则表示可以放行请求。(桶内没有数据)
如果不为0,但也没超过桶大小,则会视nodelay配置情况进入延迟处理。
而在delay情况下,nginx如何结合timer进行延迟处理的?
1 首先计算需要delay该请求多久:excess * 1000 / ctx->rate
2 将可写时间加入timer,同时将请求的可读事件加入epoll
1 | if (ngx_handle_read_event(r->connection->read, 0) != NGX_OK) { |
解析:将可写时间加入timer好理解,当timer触发式将继续执行该请求。这里首先将可读事件加入epoll中,原因是若在此期间收到了客户端的fin包,需要将该请求终止掉。
在可写事件的handler中: 下面贴出完整的代码
1 | static void |
这种延迟处理请求的做法值得学习,忽略可读事件,调用ngx_http_core_run_phases再次进去请求的处理阶段。
总结
整个limit_conn/limit_req算法从源码上就分析完毕了,从中至少可以学习到以下知识:
1 shm的使用、组织、初始化
2 如何延迟处理请求(在C层面的实现)
3 漏桶算法在nginx中的实现
4 更加优雅地组织nginx模块。
谢谢