1 源起
在逛某个论坛时,看到有一个题目:redis中的zset是如何实现的?我对redis中的数据结构还算比较了解,比如sds,double-queue skiplist ziplist等,但似乎没想起来还有zset这样的数据结构。
后来去翻书,发现zset不是数据结构,而是redis抽象出来的一种数据对象: 有序集合对象,它的主要实现形式由两种方式,一是通过ziplist的方式,而是通过hashdict+skiplist的方式。
有序集合这种数据结构(这里我依然叫他为数据结构)在使用起来非常方便,它有hash表的访问速度,也有skiplist的范围查找速度(或者叫rbtree的范围查找速度),结合了树和哈希结构体的优势,在很多场景下使用都非常方便,下面分别从源码实现和使用场景方面来加以分析,相信如果掌握了zset的实现,redis中的其他数据结构也就非常容易掌握了。
2 实现形式
我们先来看它的第二种实现方式:hashdict+skiplist的方式,这也是在数据量较大的情况下的实现方式。那么必须要先介绍下这两种结构体。
1 hashdict
- 数据结构
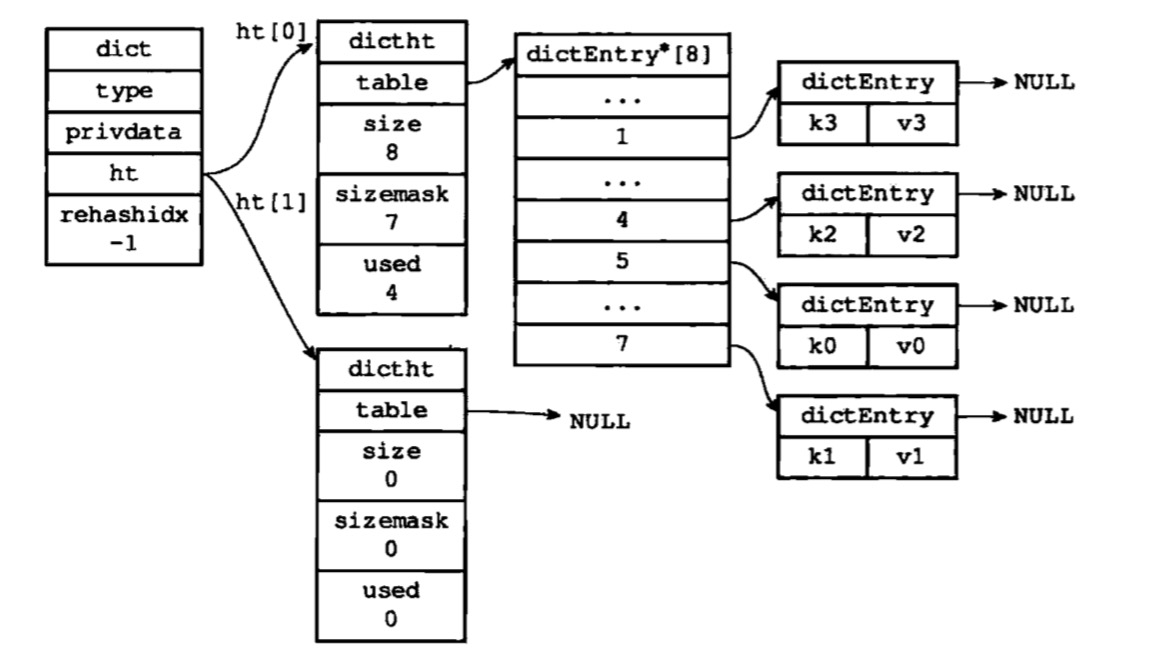
这个很好理解,就是hash表,不过redis在实现hash表时有自己的特点:下面是其结构体表示:
1 | typedef struct dict { |
其中存放数据的结构是dictht:
1 | typedef struct dictht { |
直观来看,大致长这样:
- 基本操作及特征
dict的基本操作包括插入元素、查找元素,且时间复杂度为O(1),非常适合用于快速插入、查找的场景。下面给出查找的简单代码:
1 | dictEntry *dictFind(dict *d, const void *key) |
通过dictHashKey(d,key)计算会落在哪个slot槽h中,与上sizemash,得到索引idx,通过idx得到槽表头,若有链冲突,依次查找即可。时间复杂度为O(1)。
另外:为何会查两张表?这是为了在进行rehash的时候,dict中的元素会分布在两张表中。
2 skiplist
hash表结构非常直观地可以理解,但skiplist(跳表)平时接触的不多,一般都是接触红黑树多一些,但为何redis里面没有使用红黑树而是跳表,我想是因为红黑树实现起来比跳表要复杂。另外红黑树在rebalance的时候需要锁住整颗树,但跳表只需要锁局部,不过对于单线程的redis来说这不是问题。skiplist在本质上也是一种查找类结构,即根据给定的key,快速找到其位置以及值。
下面介绍下跳表在redis中的实现以及使用场景。
- 数据结构体
1 | typedef struct zskiplistNode { |
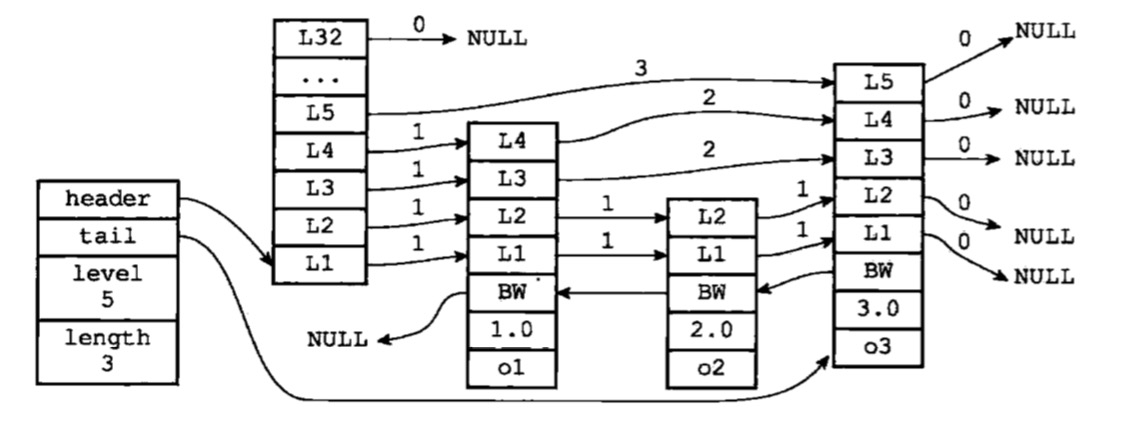
主要有两部分,node节点和list表,先分析list结构体
- header指向表头节点,tail指向表尾节点
- length表示节点总数,不包括表头节点。
- level表示层数最大的节点的层数。
下面是一个示意图:
node节点部分
- level:是一个柔性数组,可以包含多个skiplistLevel元素,每个元素都包含一个指向其他节点的指针(forward), 可以通过这些指针加快这些层来加快访问其他节点的速度。一般来说,层数越多,访问速度越快。
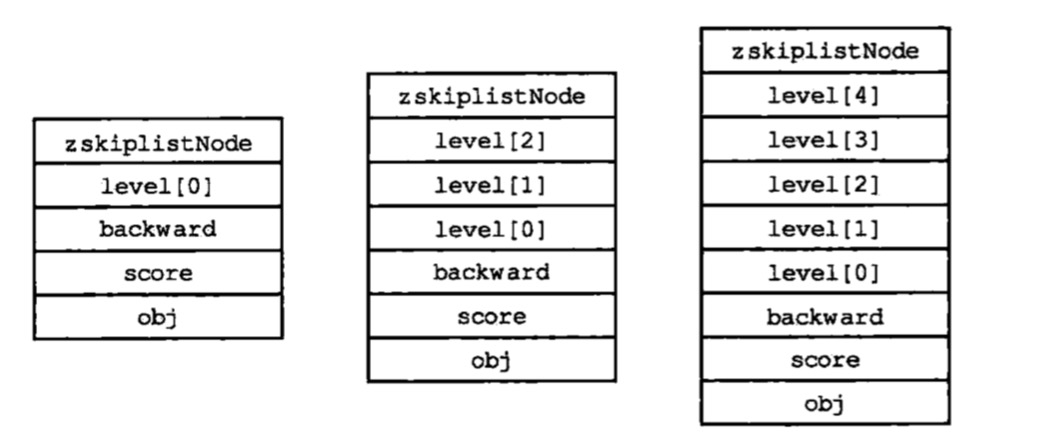
上面的3个节点,层级依次为1,3,5. 每个节点在生产之初会随机指定1~32的层级,也就是节点的高度。
其中forawde前向指针是和span结合在一起:span表示了foraward指向的节点与该节点的距离。
backward: 指向该节点的后面节点。
obj、score: 指向具体的对象、以及该对象的分值。
初看起来,跳表就像是每个节点多了很多前向指针的双向链表而已,节点的排序方式按照score的大小排序。
那么为何要这样设计,它的优势在哪里。
William Pugh 在论文《Skip lists: a probabilistic alternative to balanced trees》提到,跳跃表以有序的方式在层次化的链表中保存数据,效率和平衡树媲美,插入、删除、查找都可以在O(logn)时间内完成,并且比起平衡树,实现方式要简单直观很多。下面从它的基本操作来解析。
- 基本操作及特征
上面说过,skiplist其实也是一种list,那么它和一般的有序链表又有哪些区别,先看下有序链表。

如果要查找某个值,需要进行逐步遍历,直到找到或者找到比给定数据大的第一个节点(没找到)。当要插入一个数据时,同样要遍历。
如果我们给该链表中的节点新增一个指针,让其指针相邻的节点,这样有形成了一条链表,节点是原来的一半。
那么再进行查找,可以先在第二层链表上进行查找,如果发现遇到比查找值大的节点,然后回退到前一个节点,再在第一层链表上进行查找。
如果我们再给链表中的节点新增一个指针,让其指向与之距离为2的节点,这样形成的新链表的节点是原链表的1/3.

那么首先从第三层链表进行查找,如果遇到比查找值大的节点,回退,到第二层节点进行查找,若还是遇到比自己的节点,再回退,到第一层链表进行查找。
可以看到,如果链表足够长,这样通过高层次链表的查找方式将会跳过许多节点,大大增加查找效率(再也不是遍历操作),这也是跳表的名字由来。
如果深入来看,其实这种查找方式类似与二分查找,只不过是将二分查找的思想应用在了有序链表上。
而在实际使用中,没有这样严格的按照层次递增、节点数减半的特征,而是每个节点的层级是随机的,那么仅仅依靠随机的层级构建出来的多层级链表能够保证skiplist有良好的查找性能吗?通过数据统计,它的查找效率依然接近于O(log(n))。参考:
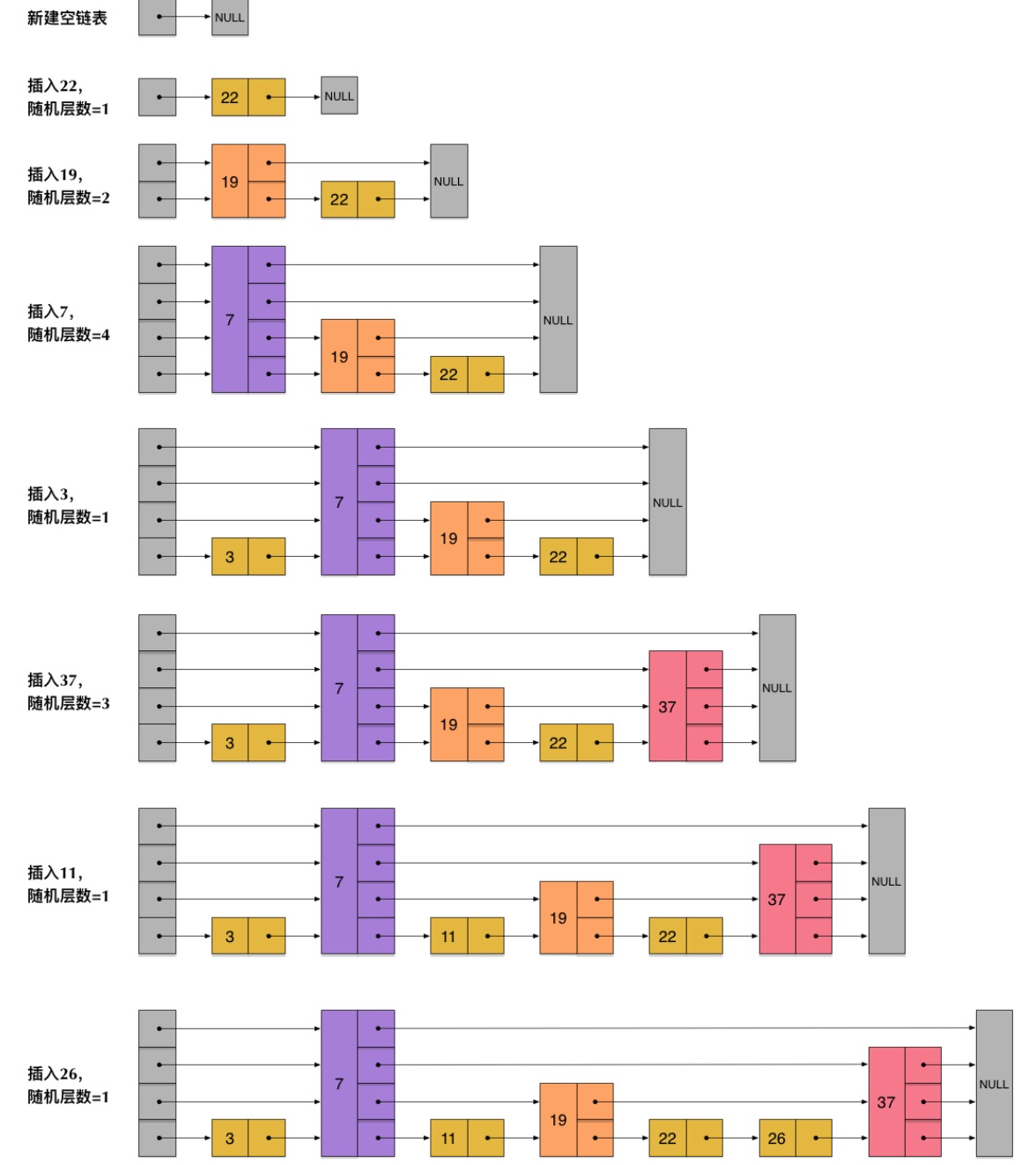
谈到这里应该对skiplist的工作原理清楚的了解,那么来比较下和典型的几种查找结果的差异:
1 skiplist与hashdict:hash表的查找效率是O(1),但有个缺点是hash表不是有序的,只能做单key的查找,如果要做范围查找无能为力。(STL中通过rbtree实现了有序map)
2 skiplist与rbtree:rbtree也是有序容器,但如果进行范围查找,skiplist的实现更为直观。
3 rbtree的插入删除涉及到rebalance,但skplist的插入删除只需要修改相邻节点的指针指向,更方便
4 最重要的是,skiplist的实现比rbtree更为简单。(虽然nginx实现了优雅的rbtree)。
3 zset的基本操作
zset在redis中是有序集合对象的名称(sort set),适合用在类似排行榜等应用场景。结构体如下:
1 | typedef struct zset { |
如果用zsert来表示某个课程的各位同学分数:
1 | Alice 87.5 |
存放到zset中去:
1 | 127.0.0.1:6379> zadd math 87.5 alice |
其中zadd将各个记录加入zset math中, zrevrank 逆序排序输出序号, zscore输出相应key的分数,zrevrange逆序将排序范围内的key输出, zrevragebysocre逆序将分数返回内的key输出。
如果我们结合skiplist来分析这几个操作,大致看下他们分别是如何实现的:首先要明确一点:再skiplist中查找是用score来作为key。
zscore: 根据key来输出score,由于skiplist是通过score来排序的,查找并不是通过key,这样zscore命令单由skiplist完成不了,实际上是通过hashdict来完成。
zrank(zrevrank): 输出某个key的排序:只要输入参数是key,需要先到dict中拿到相应key对应的score,然后再通过score到skiplist中去查找。所以需要dict+skiplist合力完成。如何通过skiplist查到排序:还记得之前的level数组元素中的span么?将沿途查找节点的各个span累加起来就可以得到排序了。
zrangebysocre(zrevrangebyscore): 输出分数范围内的key:直接在skplist查找,这是典型的范围查找。
zrange(zrevrange): 输出排序范围内的key: 由于span直接和排名相关,通过不断累加span以让其在给定的范围内,可以逐步找到一条路。
如果理解了skiplist+dict的工作原理,这些命令的实现你也应该清楚其逻辑了, 以后看到其他关于zset的命令基本上都可以大致清楚其实现逻辑,再结合源码可以更清楚地理解。