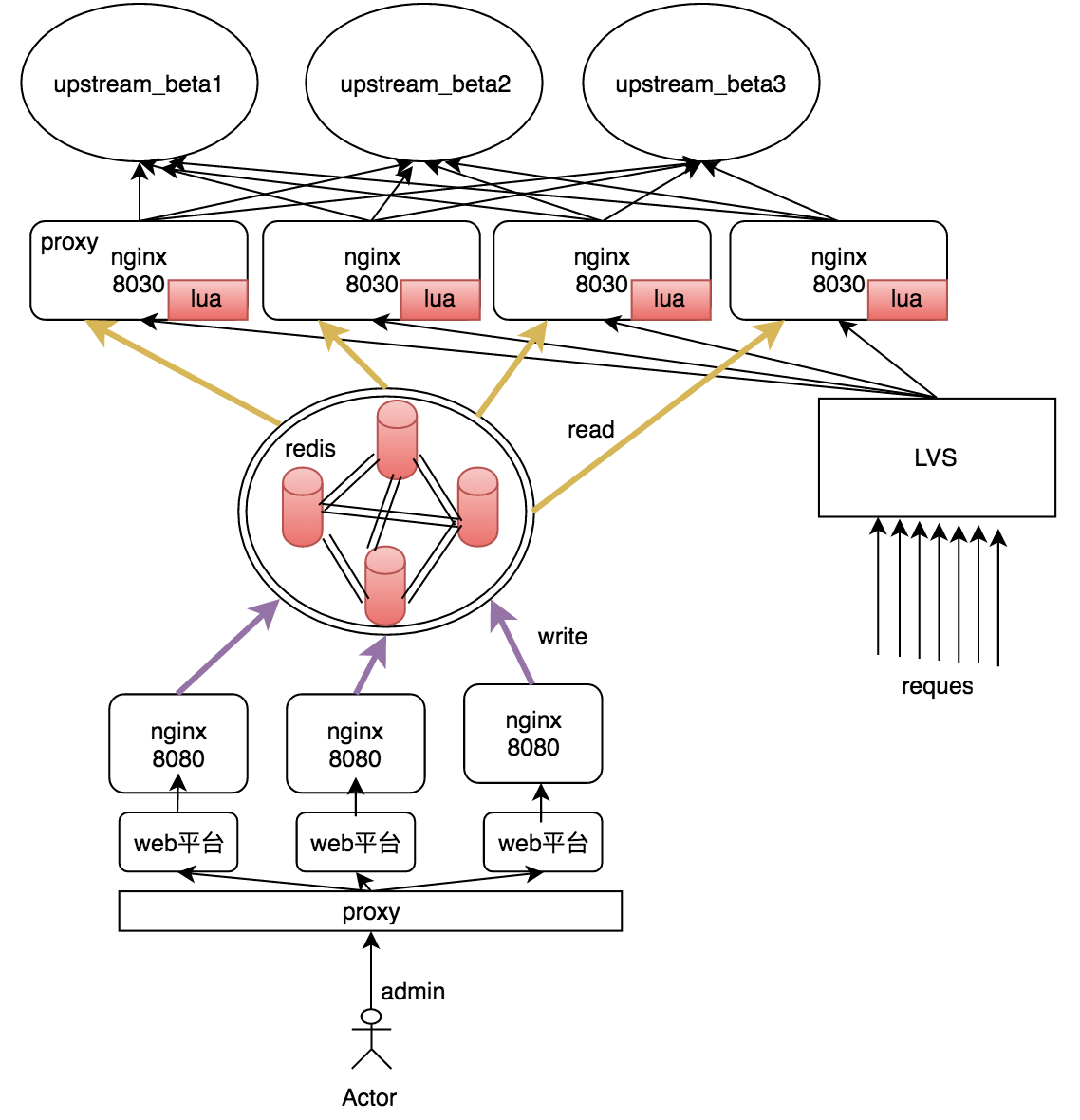
背景介绍
细化分流和降级的项目依赖redis存放分流和降级规则,为了保证redis的高可用,需避免其单点故障和数据丢失。整个系统的架构图如下:
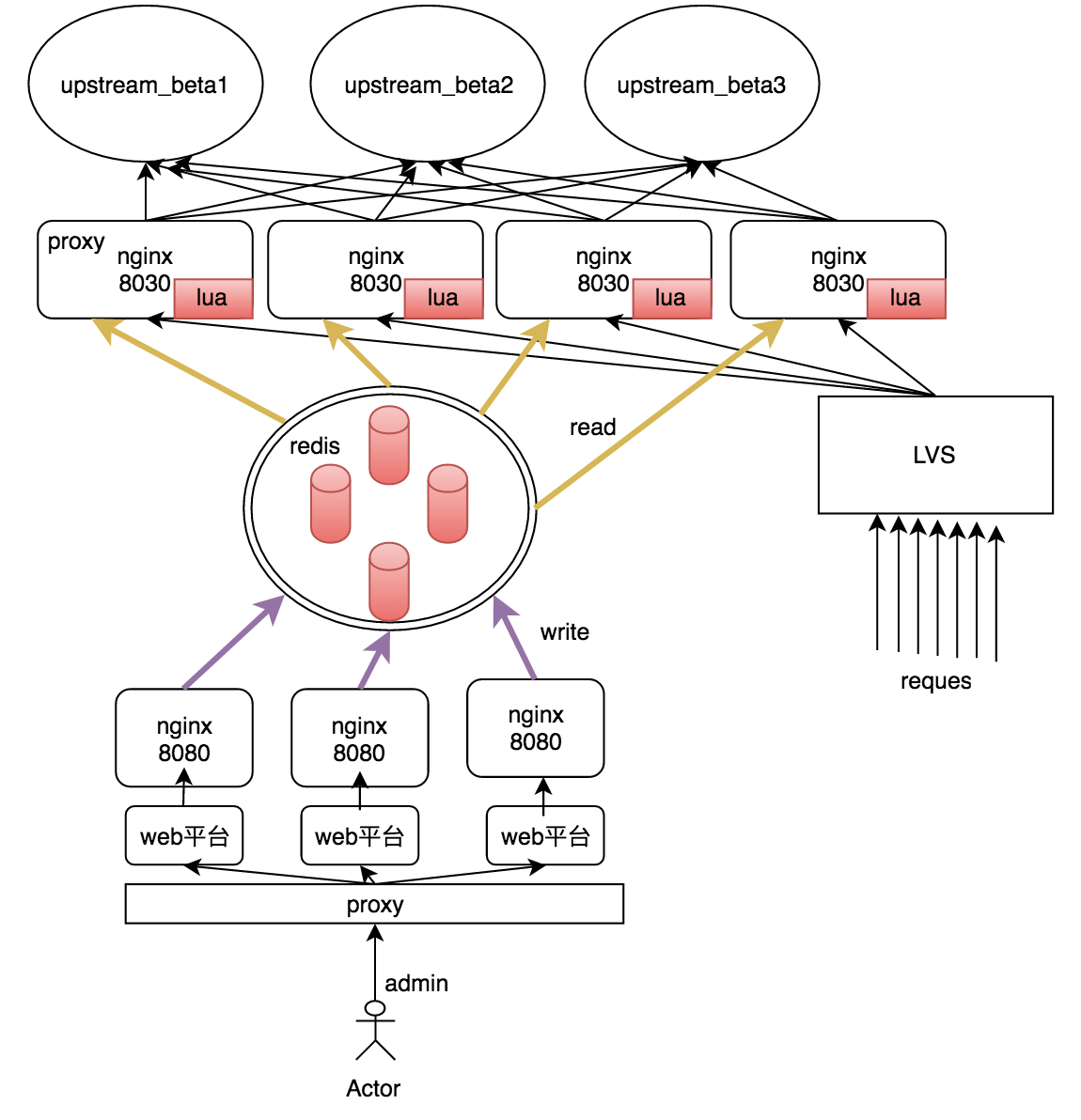
在管理端,通过多个管理实例来避免管理端的单点问题,将策略规则写入redis。在业务端,多个Nginx代理从redis中读出策略规则并缓存在本地的lua缓存中,结合用户请求,最终将其分流到不同的上游集群。
尝试解决
1 当某个redis挂掉后,其上面的数据需要有备份,不能丢失。
2 整个redis集群须提供对外统一的访问接口。
为此考虑了以下几种解决方案:
1 主从模式
2 代理模式
3 集群模式
主从模式
若用redis主从模式,其接入架构图可以为这样:
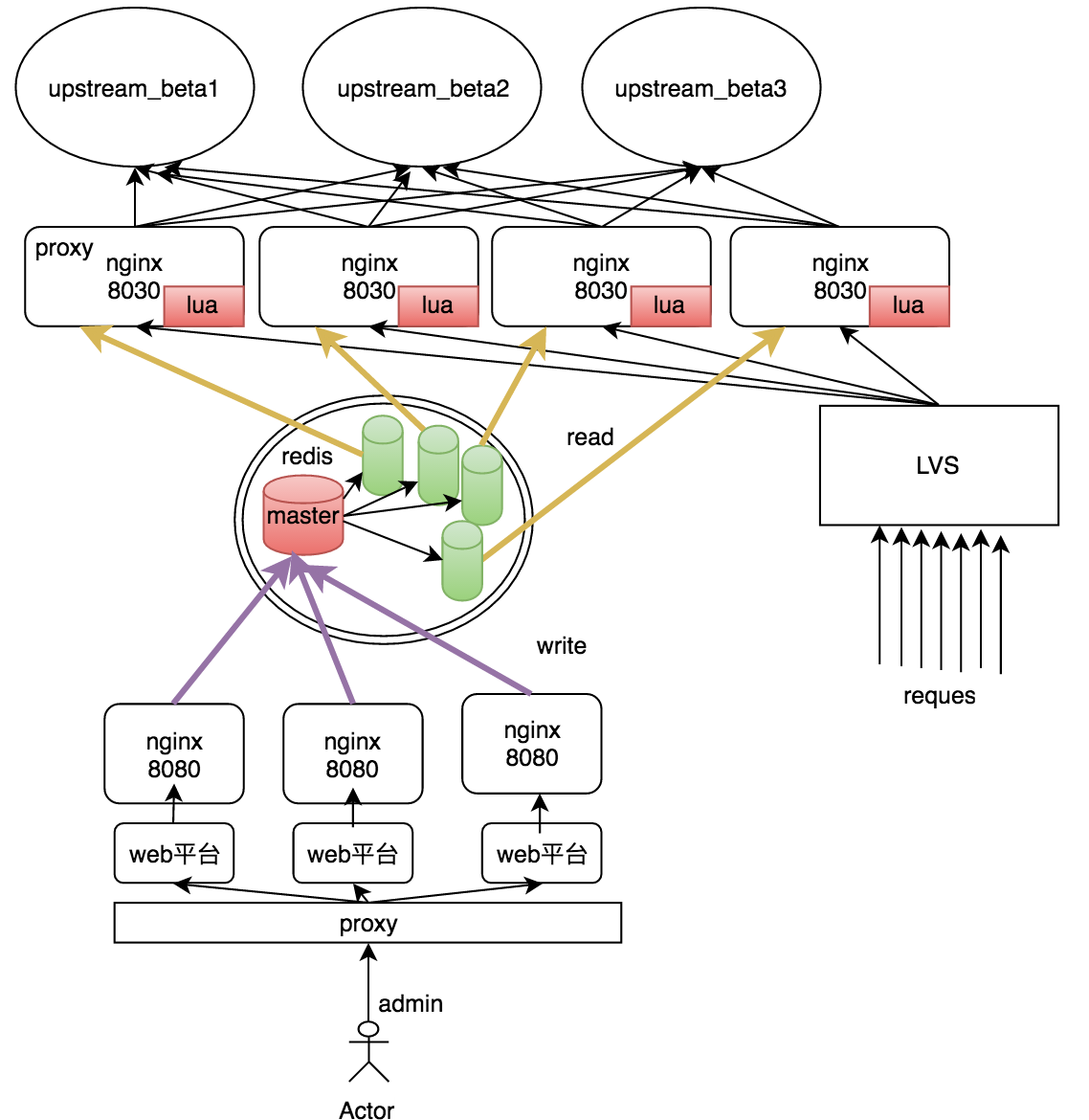
1 在所有redis中有一个主库,其余均为从库,所有从库始终保持和主库数据同步。
2 所有的管理机均将策略写入主库,各个业务机将从各自的从库中读人。可以将从库于业务机部署在同一主机提高读取速度。
该方案的特点:
1 实现简单。redis主从关系设置方便,且有现成的接入单个redis的lua接口。
2 容灾性差。所有管理机都依赖于唯一的主库,造成单点问题(虽说系统依然可以正常处理业务),且业务机访问单个redis从库,也造成单点问题。
3 。。。
代理模式
为了让多个redis对外提供统一的访问接口,尝试采用redis的代理服务。根据调研,目前业界有两种成熟的解决方案:twemproxy和codis。其架构图如下:
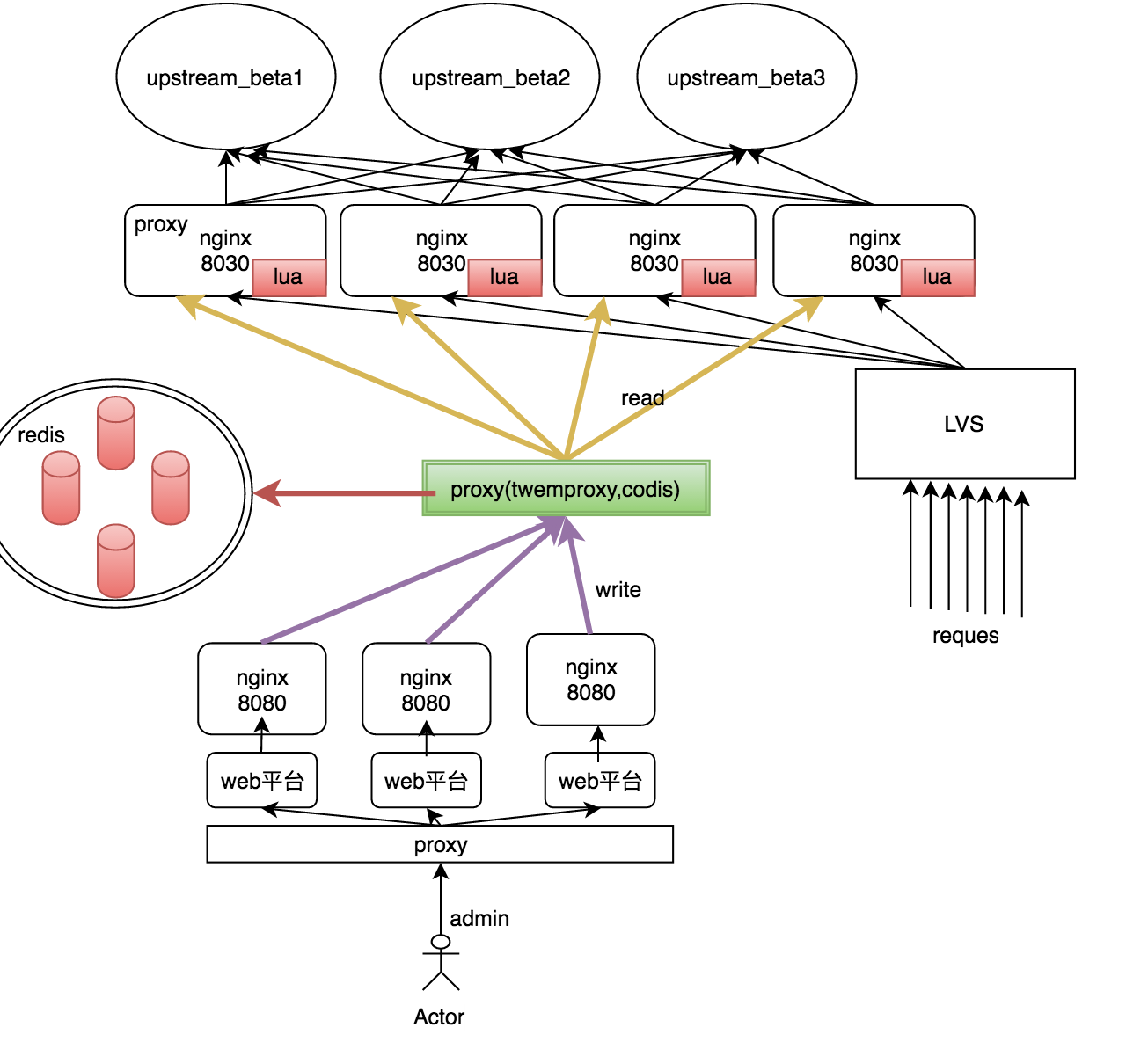
通过代理,所有接入redis的请求都由代理来处理。
该方案的特点:
1 统一接口。代理对外提供了所有访问的统一接口,且可以兼容访问单个redis实例的lua接口
2 容灾较差。代理将数据写入或从redis集群中读出是采用分片的方式,从中选择某个redis来进行写或读。
如果某个redis挂了,其上面的数据依然会丢失。
针对2进行的改进是:对每个redis做主备,其架构如下
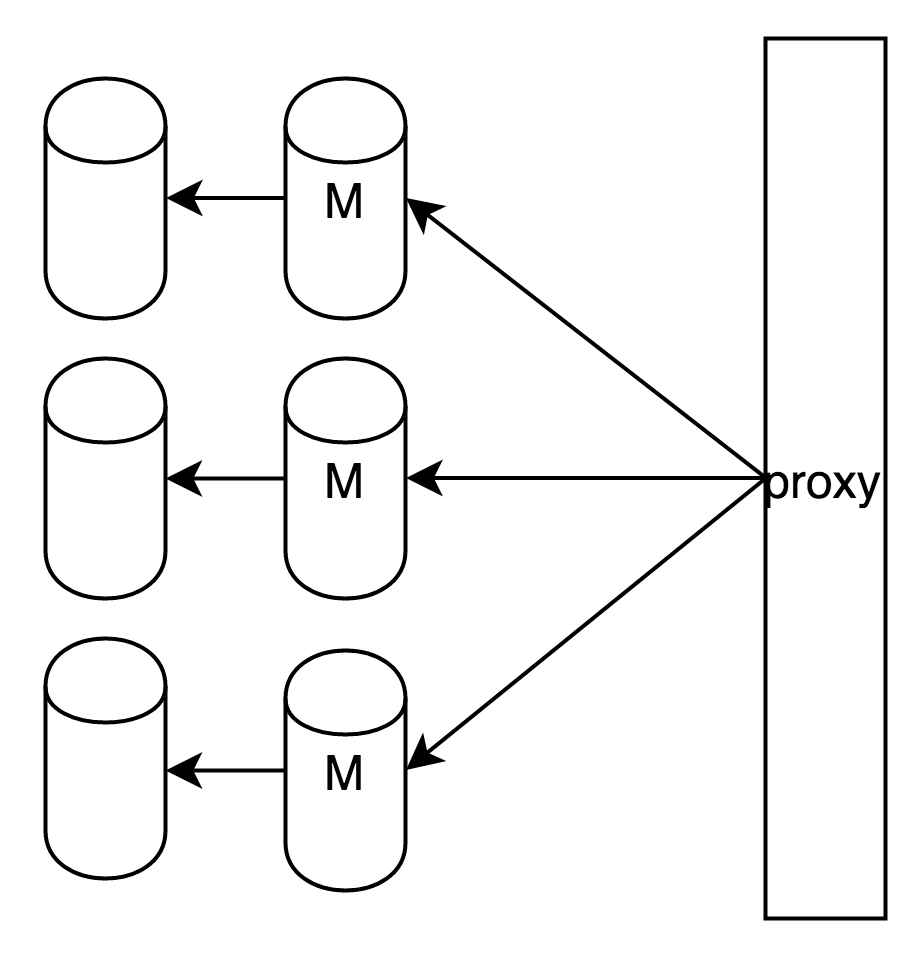
这样虽然保证了数据不丢失,但主库挂掉时,从库需要手动升级为主库,运维麻烦。
集群模式
集群模式是redis在3.0后的分布式解决方案,可以很好地满足上面的两个要求:1 对外提供统一接口 2 数据一致性且不丢失。其接入架构图如下:
集群中的所有redis都互相传递消息,且按照分片的方式进行存储数据。在本节介绍redis集群的部署方式后,在下一节介绍redis集群原理。
集群部署
1 运行多个处于集群模式的redis实例
这里以6个为例。要使redis处于集群模式,需在配置文件里面添加:

cluster-enabled表示是否以集群模式运行。其它字段意义可参考官网:http://redis.io/topics/cluster-tutorial
然后运行6个实例
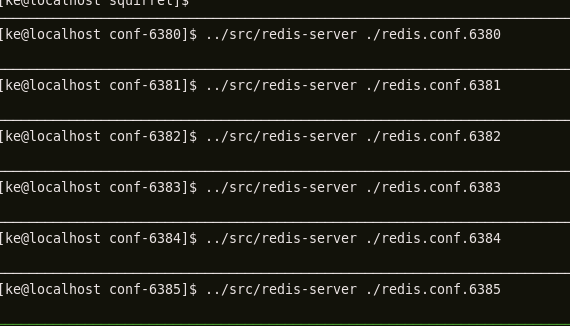
其客户端监听端口以此为6380,6381,6382,6383,6384,6385。
2 安装依赖
上面的6个实例虽然处于集群模式,但是各自为战,并没有构成真正意义上的集群,为此需要将其构成集群。
在redis包中有将redis实例构成集群的管理包,但运行其管理包需要安装依赖环境,包括ruby,gem等


3 构成集群

其中redis-trib.rb是构成集群的命令,create表示创建集群,–replicas 1表示集群中的每个主节点都将附带一个从节点。
4 安装完成
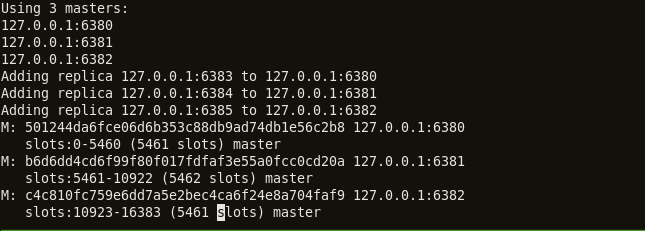
在集群中的6个节点中有3个主节点是负责真正写入和读出数据的,三个从节点将为其主节点备份,并在必要自动时候升级为主节点(没错,是自动升级,下一节会介绍其原理)
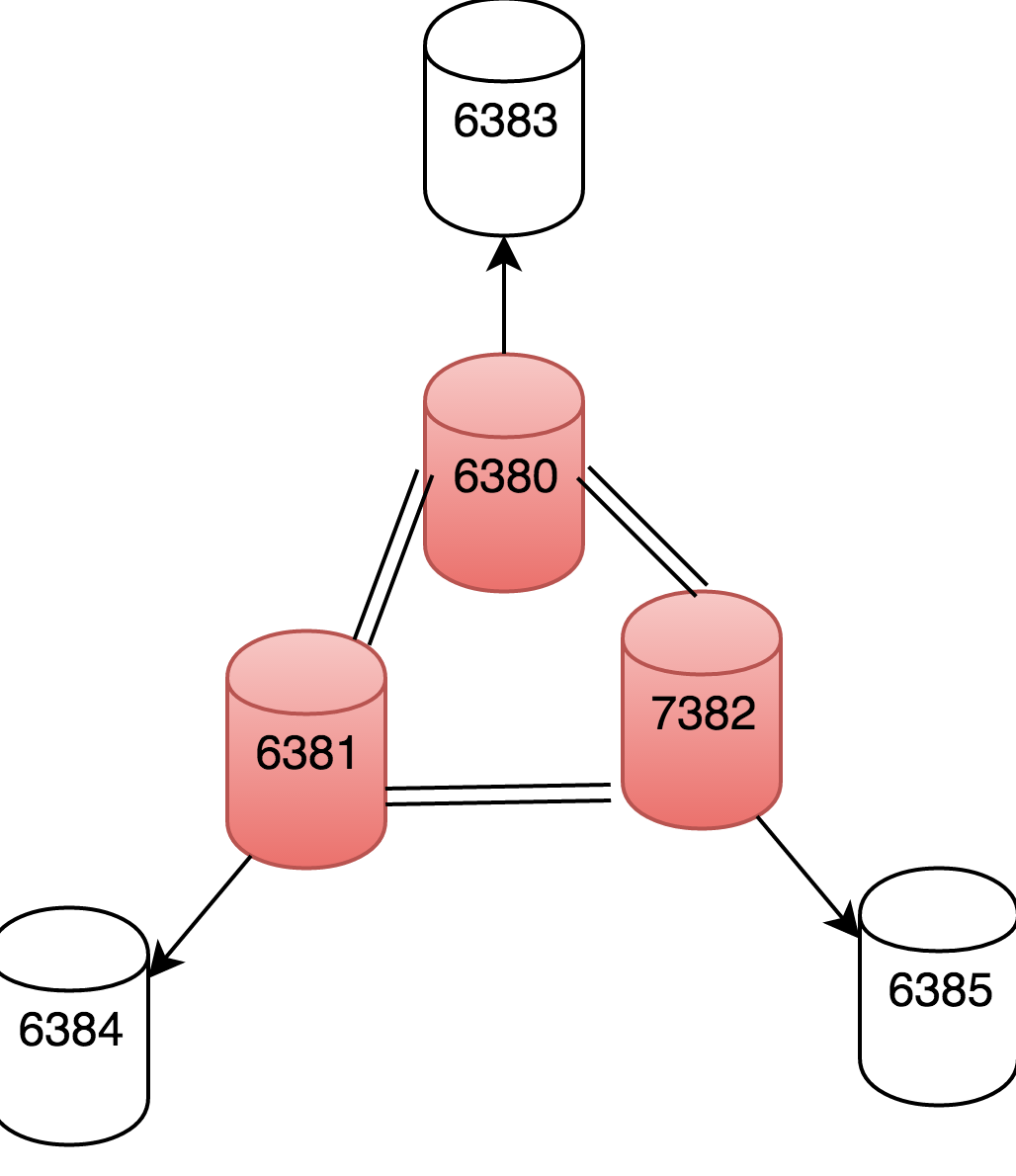
PS:
1 红色的为主节点,该集群也就表示由这三个主节点构成,其从节点只是为其备份数据,并不参与集群的数据的读写。
2 每个节点(包括从节点)都会感知集群中的每个节点的状态,且每个主节点都可以设置多个从节点。
3 主节点间的数据不冗余(即每个主节点间的数据都不是备份关系),而是经过分片处理数据。每个节点处理一部分“槽位”,redis集群方案共设置了16384个槽位。
redis集群
节点
开始时,集群中的每个节点都是单个的集群,它们之间通过“握手”来构建整个系统集群,以上面的三个主节点组成的系统为例,构建集群的过程如下:
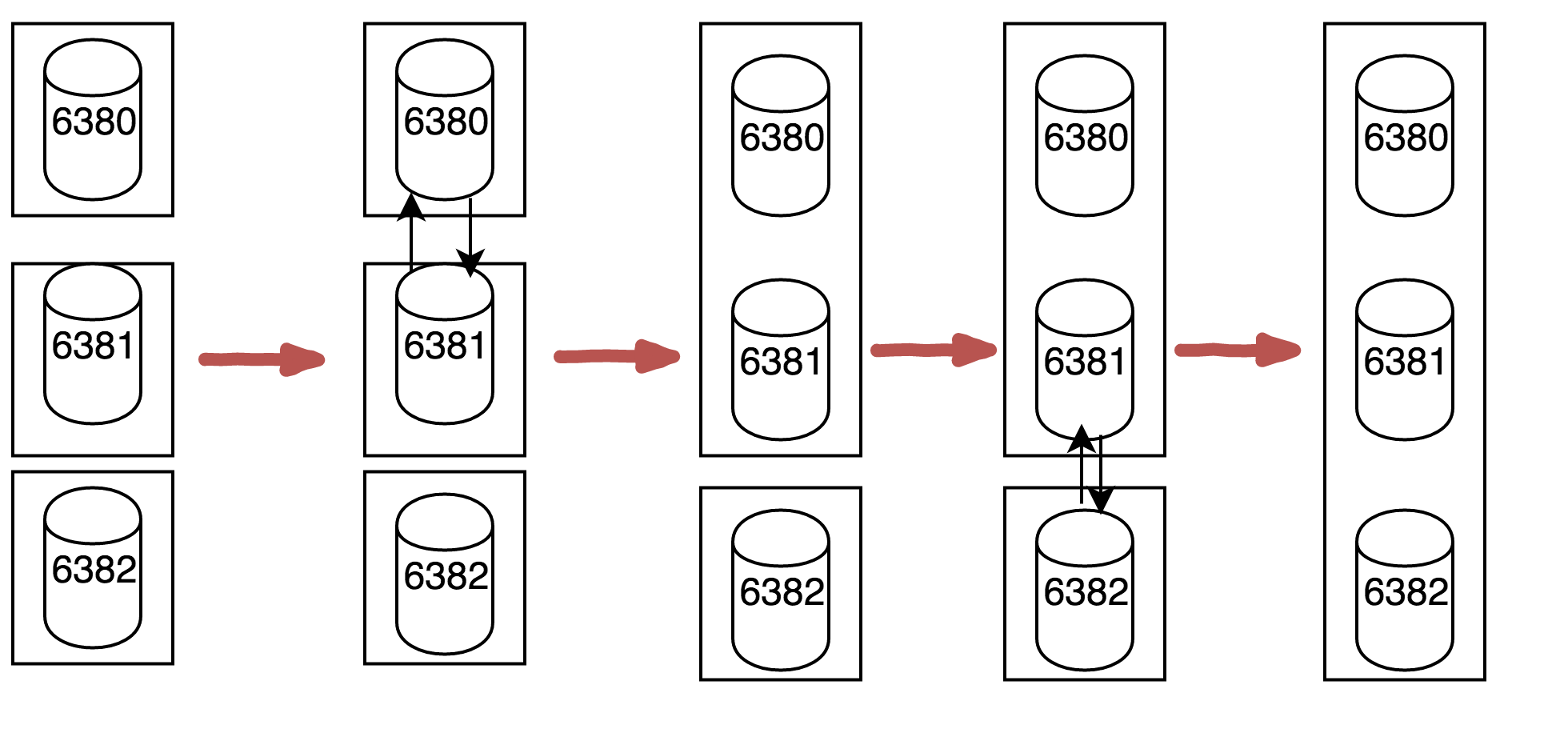
首先6380节点和6381节点相会握手成功后,其会构件为一个集群,然后6381和6382握手成功后,所以的节点都加入了同一个集群。
在集群中的每个节点和在普通模式下运行的节点所代表的数据结构不同:clusterNode.
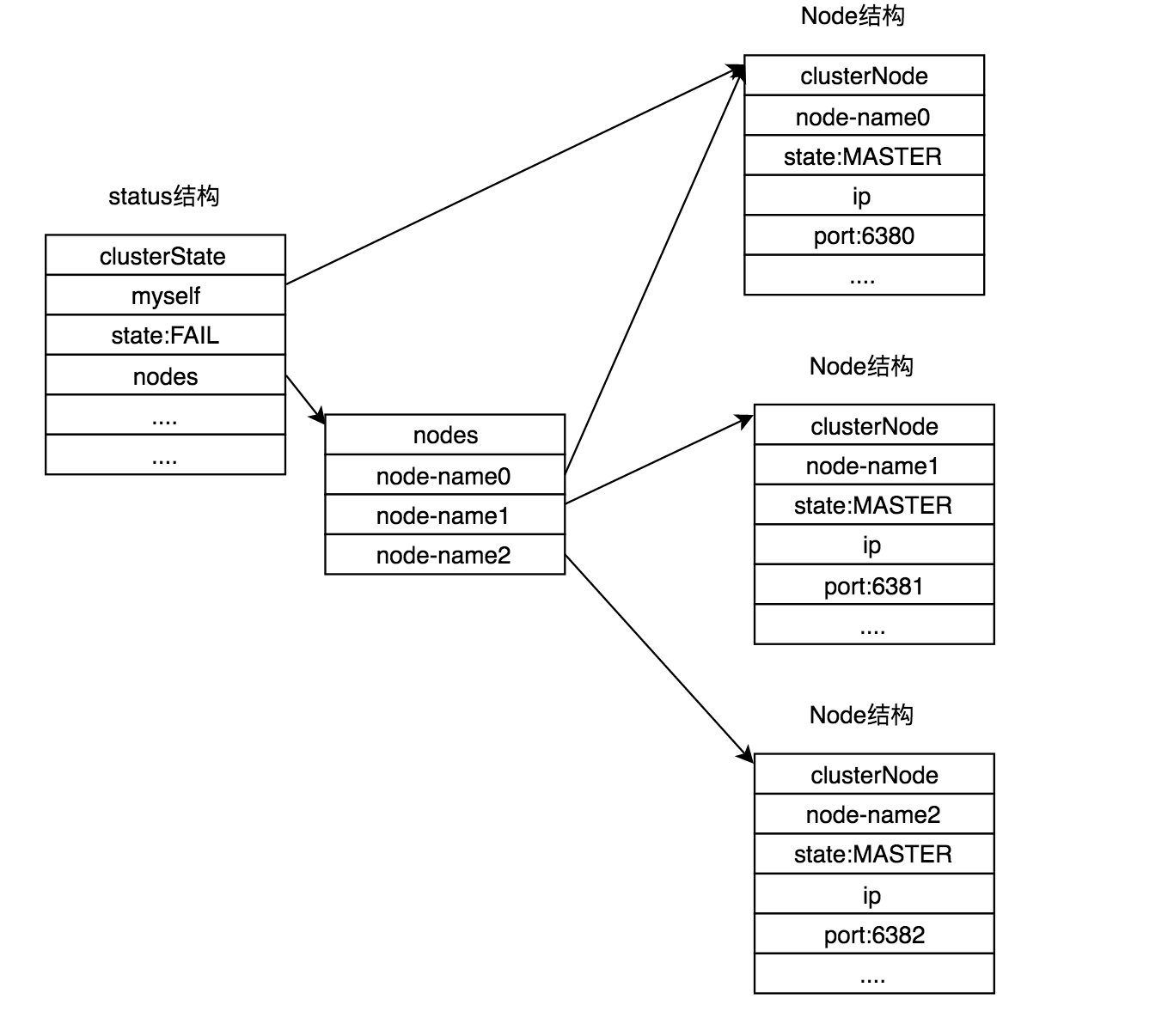
每个节点中都有感知集群中其它节点的信息。
槽指派
Redis集群是通过分片方式来保存数据的:整个集群的实现一共分为16384个槽(slot),这些槽在空间上组成环状。集群中的每个KV对都属于这16384个槽中的一个,且每个集群中的主节点可以处理0个或者多个槽,每个槽只属于一个主节点。
当16384个槽都被处理时,我们称集群处于上线状态(OK),可以通过每个主节点的clusterstatus结构体的state来标示。否则,任意一个槽没有被集群节点覆盖到,那么集群将处于线下状态(Fail)。
处于上线状态的集群中的每个主节点都感知每一个槽分别被哪个主节点处理的:
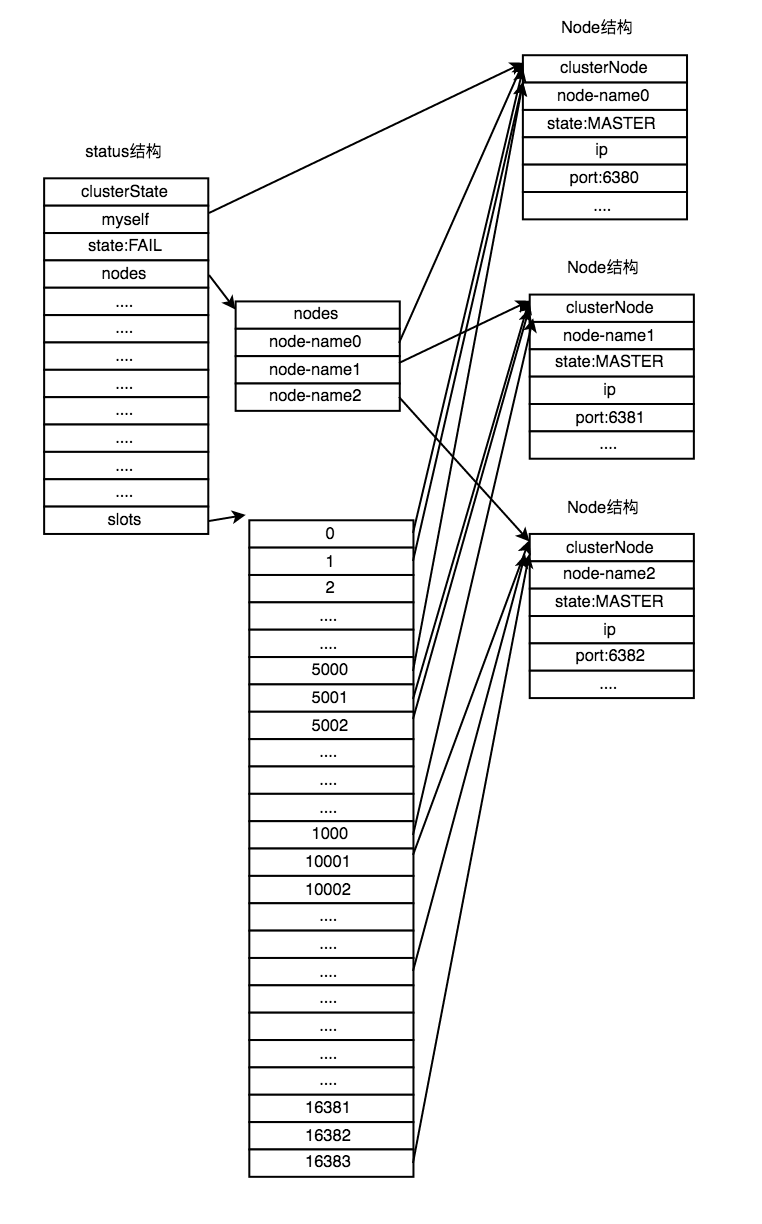
如上所示:槽0-5000被节点6380处理,5001-10000被节点6381处理,10000-16383被节点6382处理。
这样每个节点都能迅速掌握哪个槽被哪个节点处理。
MOVED错误
当集群接受到redis命令时,首先计算该键值对应的槽位,然后判断该槽位是否被当前节点所处理,所是,则直接处理,否则将返回MOVED错误给客户端,客户端会通过MOVED错误的信息转向正确的主节点进行处理。其答大体步骤如下:
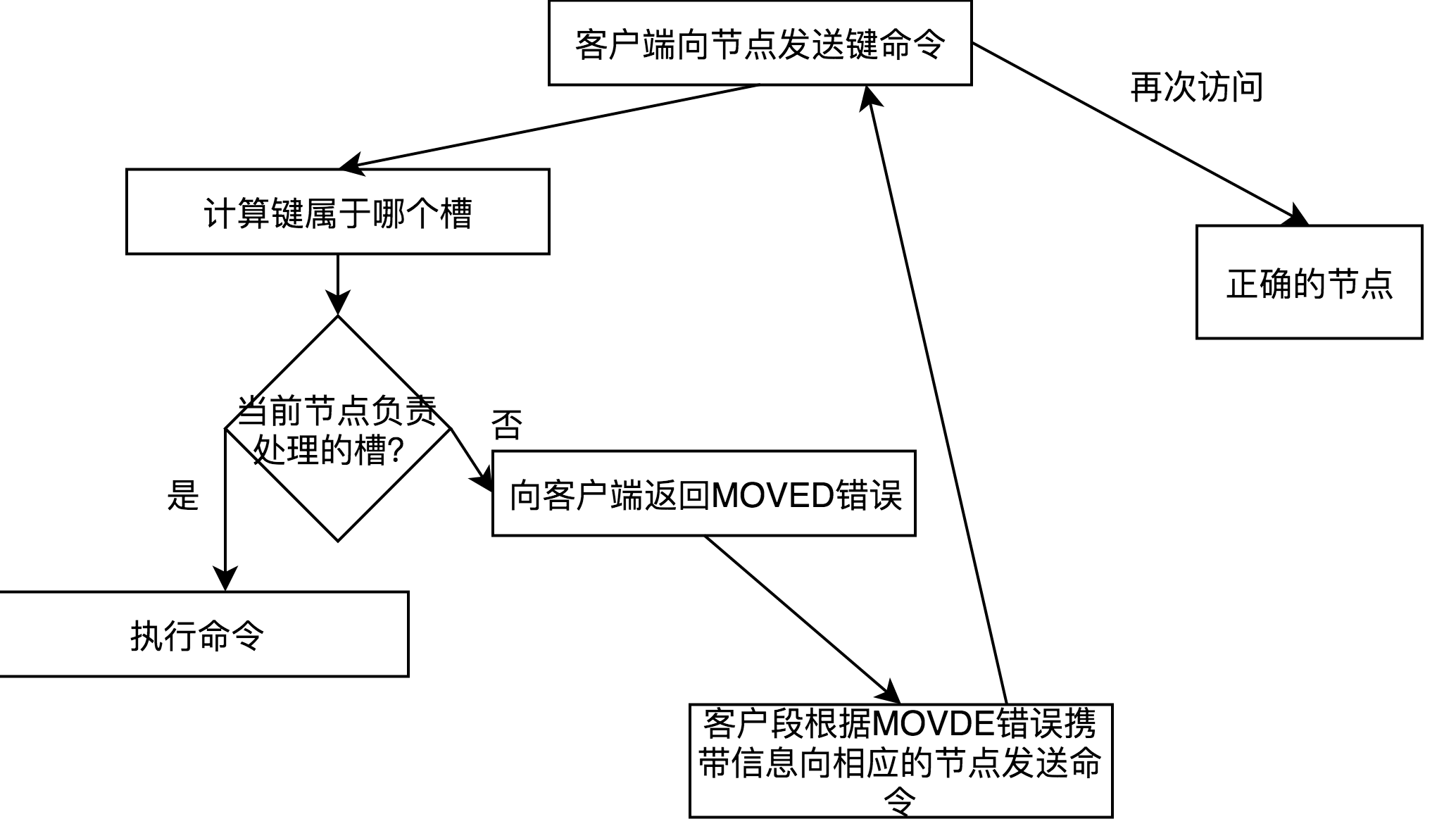
PS
1 键值与槽位的关系:
通过键值来计算槽位:CRC16(key)&16383 。即先计算键值的CRC16校验和,然后得出一个介于0~16383间的整数做为key的槽位。
2 MOVED错误只有支持集群模式的客户段才能够正确处理(继续访问正确的主节点),否则将打印错误。
复制故障转移
如果集群中只包含主节点,那就大大降低了它的高可靠性,一般集群中的主节点都会有从节点。从节点主要用于在相应的主节点发生故障后代替成为主节点,实现故障转移,达到高可靠的特点。而这个过程在集群中是全部自动完成的。
1 集群中的每个主节点都感知各个主节点的从节点。
2 若集群中超半数的主节点认为某个主节点故障,则该主节点被下线。
3 某个主节点被下线的消息会被广播到所有节点(包括从节点)
4 当从节点(们)发现自己的主已经被判定为下线,那么这些从节点会向各个主节点发送选举请求,请求各个主节点支持自己成为主节点。
4 只有每个主节点有投票选举权,且只有一票。
5 若某个从节点已经得到过半主节点的投票,那么会将自己升级为主节点,同时接管原来主节点所处理的槽位,并向集群广播自己被选举成功的消息。
接入细节
想让上面的Redis集群接入到分流和降级系统中,需要有专门的Lua接口来接入redis集群。根据支持集群模式的C客户端和支持普通模式lua接口,可以构造支持集群模式的lua接口。
推荐:https://github.com/cuiweixie/lua-resty-redis-cluster
PS:这个客户端有少许bug:
1 需要把local关键字加在redis实例前面,参考其PR
2 在高流量情况下,由于超时重试机制,导致一个请求创建了最多18个redis实例和超时timer,把LUA虚拟栈跑爆了,这个需要改造下