前言
Nginx的高性能得益于其优秀的网络架构模型。为了充分发挥多核CPU的优势,让每个进程都“亲缘”一个CPU,减少上下文切换带来的损耗,同时也需要解决多个进程监听同一个端口带来的各种问题,本文将简要描述下Nginx的网络架构的演变过程。
网络模型
模型一
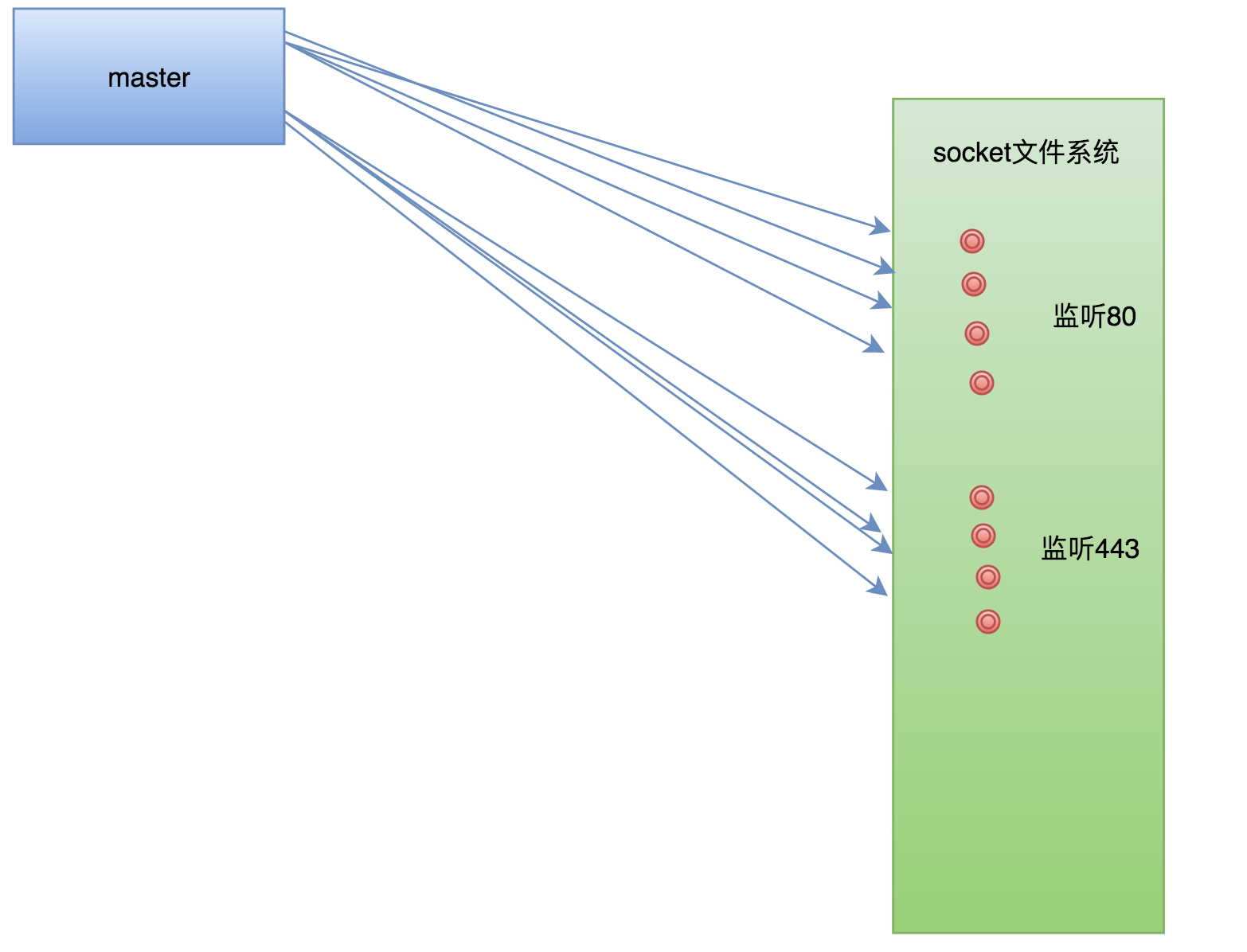
Nginx是单主(master)多从(worker)模式的进程架构,Master进程在解析配置文件的时候,对于每个监听的端口,将创建一个监听socket套接字,为了描述,这里假设在配置文件中开启了80和443两个端口。其网络模型如下:
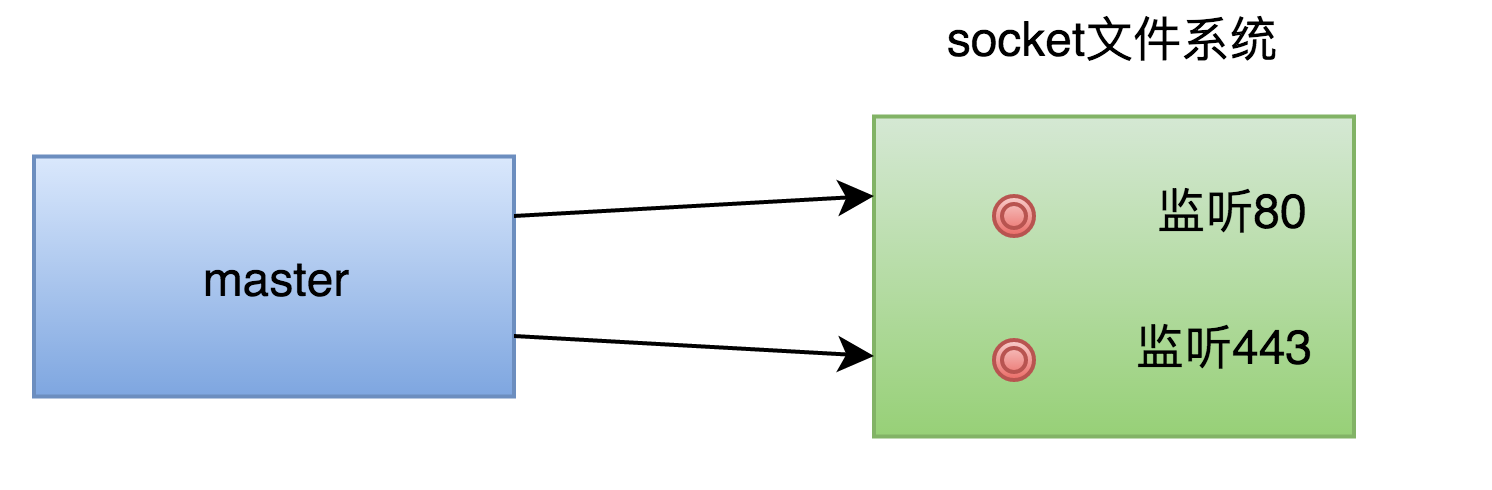
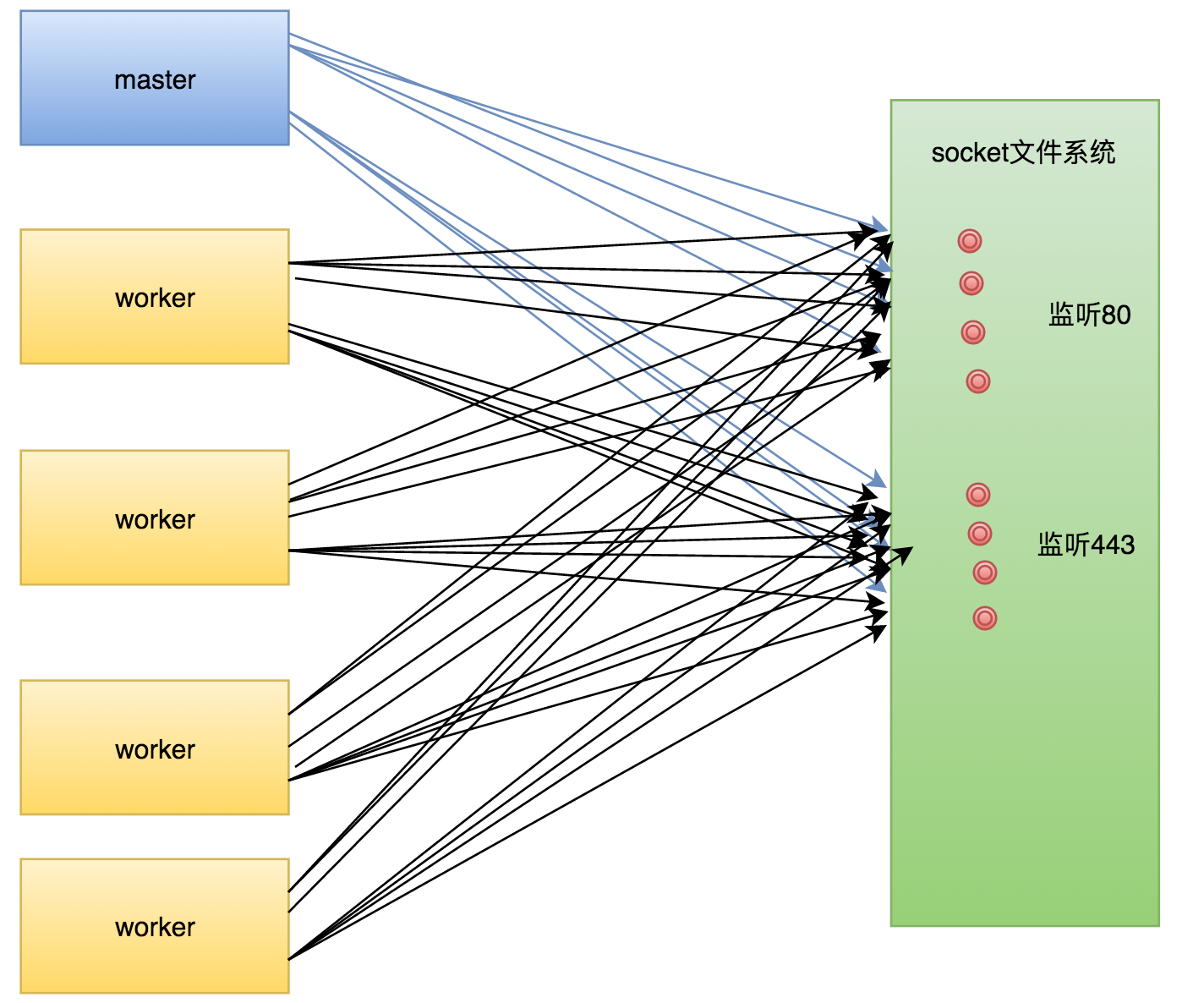
在解析完配置文件后,master进程开始创建子进程,这些子进程会进程master的资源,当然包括套接字等,如果开启4个worker,则其网络模型如下:
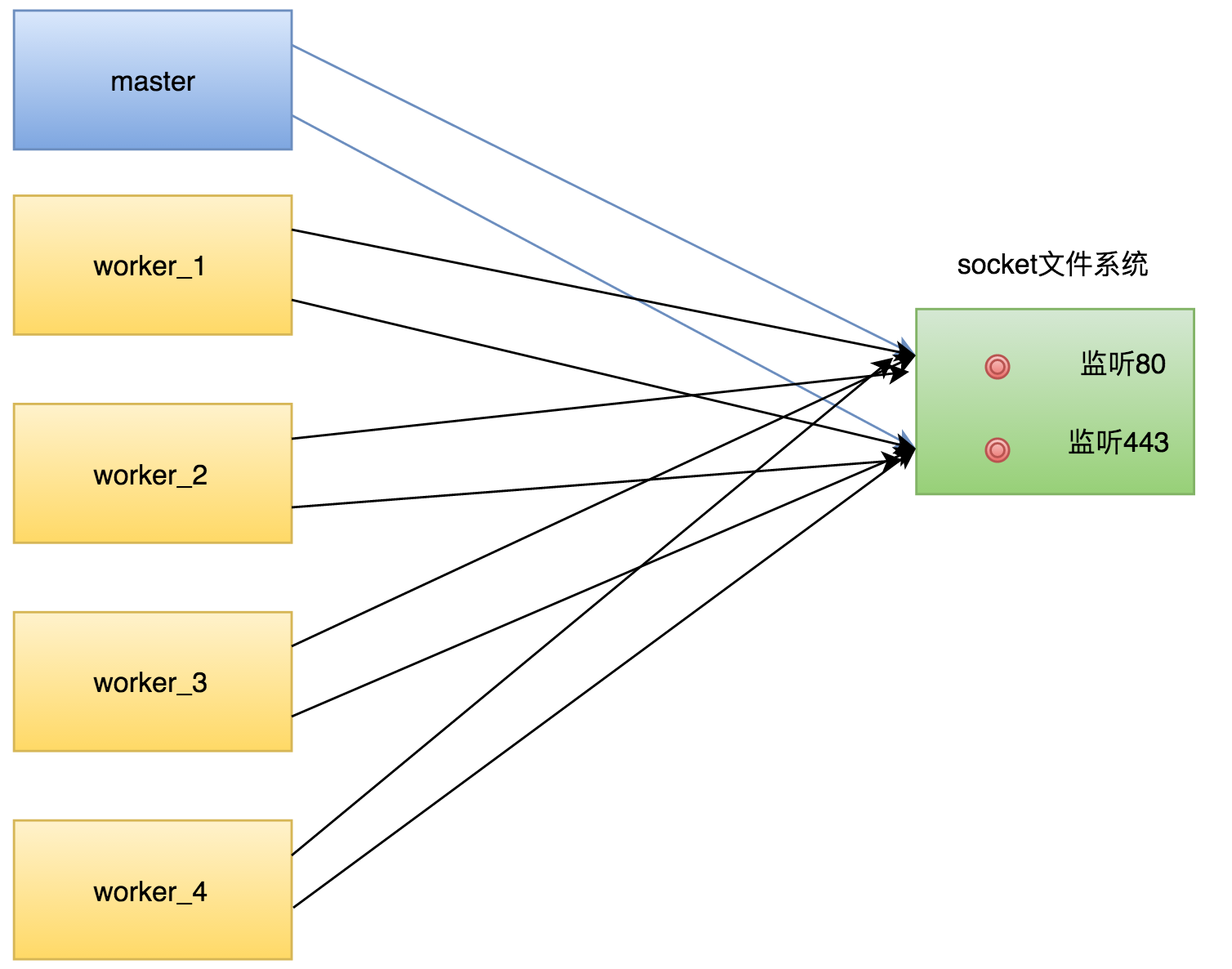
这时候,如果有请求来临,内核会唤醒所有的进程,这就是惊群现象。(先不谈Linux内核是否解决了惊群现象,Nginx作为一个跨平台的服务,必须从自身解决这个问题)
传统的网络服务(如apache等)会采用每个请求分派一个线程来处理,而Nginx采用的IO多路复用机制(有时候也叫做事件驱动),如在Linux平台的epoll,BSD平台的kqueue等,配合非阻塞的soket API,充分利用了CPU,提升了网络服务质量。下面会以Linux平台下的epoll为例,说明Nginx是如何解决惊群问题的。
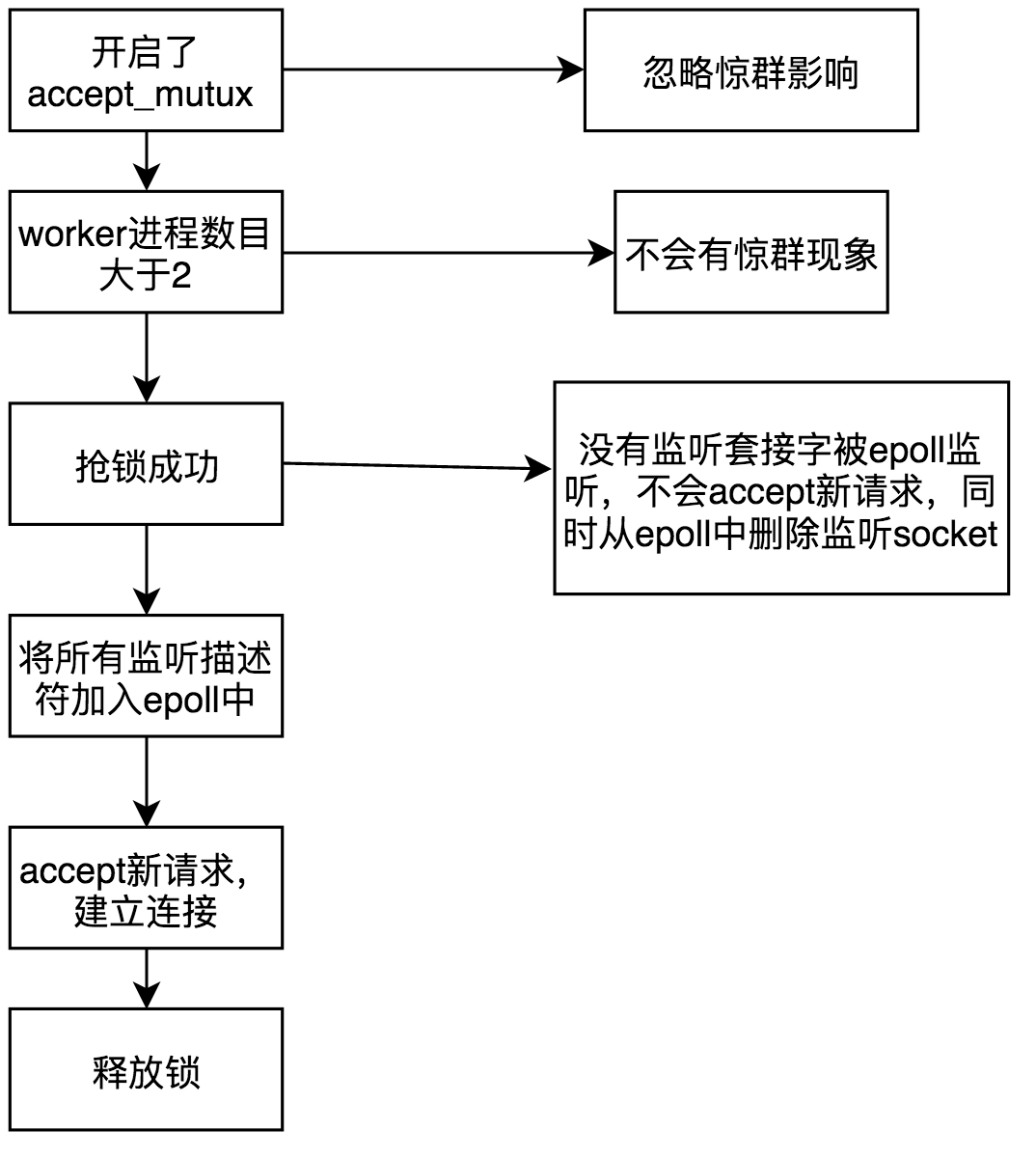
1 各个worker进程会创建自己的epoll句柄(不包括master)
2 接着会判读,管理员是否开启了惊群锁且worker进程的数量大于1。
a,惊群锁默认是关闭的,如果管理员显示开启了accept_mutux off,则会禁用,Nginx就不会解决惊群问题。
b,如果worker的进程数量小于2,那么不存在惊群问题,Nginx也会不解决惊群问题。
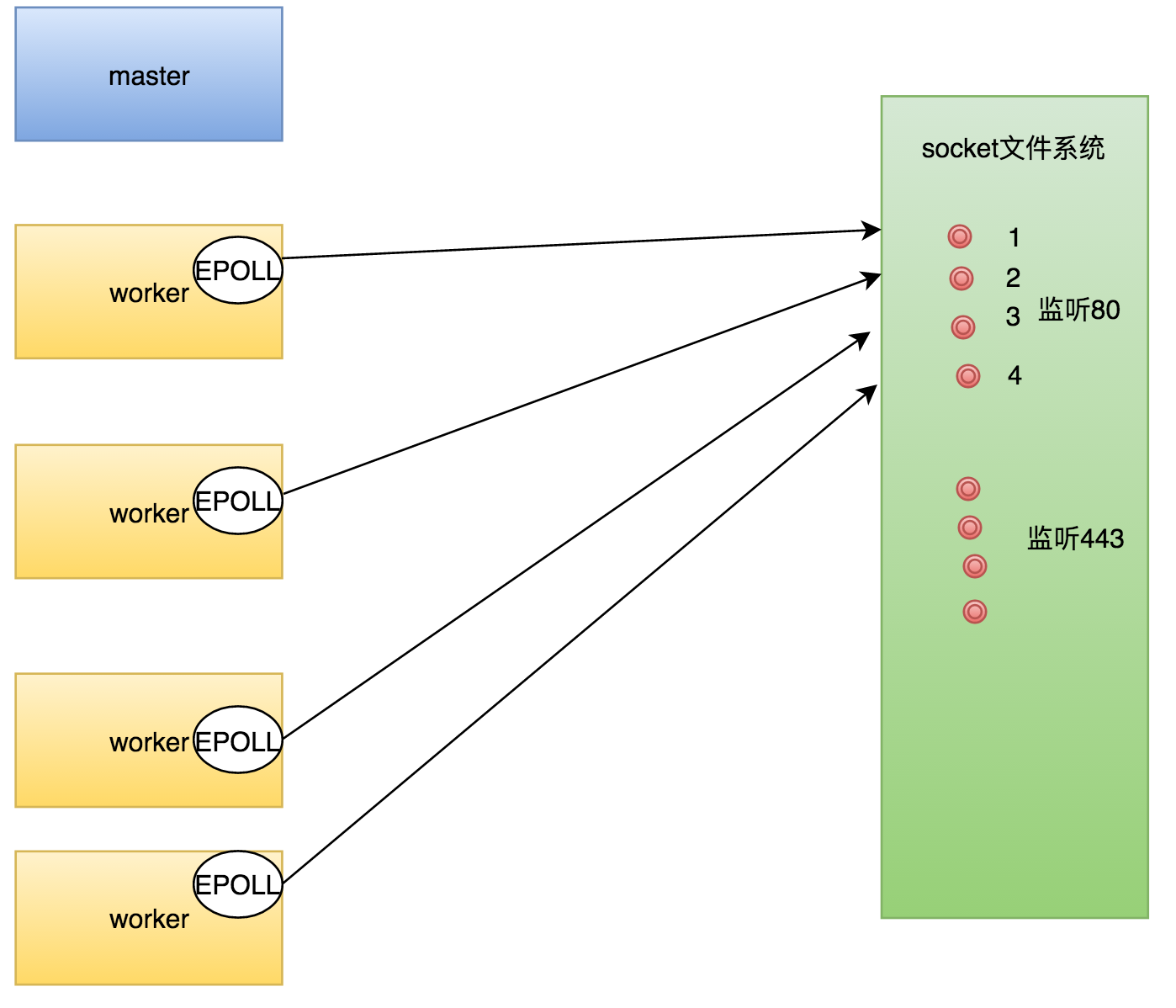
3 如果惊群生效,则每个worker首先不会去把监听套接字描述符加入自己的epoll系统,而是先去抢一把自旋锁,即对所有监听套接字的“控制权”。
4 抢到锁的worker进程,会将所有的监听套接字都加入自己的epoll中,而没有抢到worker会首先删除自己epoll中监听的监听套接字(如果有的话)。这样当有新请求来到时,只会有一个worker被唤醒,从而解决了惊群的问题。
其流程图大约如下:
小结:
1,在请求量不是特别大的情况下,Nginx这种解决惊群现象的手段提升了网络服务质量,避免多个进程无谓的被“唤醒”去accept请求失败而导致的损耗。
2,然后现在在很多情况下证明:当并发请求量过大时,这种依靠抢锁机制解决惊群的手段,会导致处理请求的效率下降,所以现在较多的建议是关闭accept_mutux锁,让Nginx不解决惊群。
模型二
在第一种模型下,通过抢锁来保障每次新请求到来时都只会有一个worker去执行accept,避免其它worker的无谓消耗。这种情况在高并发场景下受到了质疑,事实上,在高并发情况下,关闭惊群锁而不让Nginx处理“惊群”反而会提升处理效率。下面举一个例子说明:
试想,有一群小鸡,你撒谷粒给这群鸡吃。
a,一粒粒撒的时候,如果不加处理,每个鸡都会跳起来,但最终只有一只鸡能够吃到这粒米。
所以在一粒粒撒的时候,需要有锁,不能让每个鸡都跳起来,这样浪费它们的精力,必须要让它们遵守秩序,一个个来(加锁)
b,然而,如果你撒了一大把谷粒,这时候还让它们一个个来,这样是很不合理的,所以,在撒大把谷粒的情况下,这些鸡全部跳起来抢食才是科学的,这样才能更加快速地消耗掉这些谷粒。(不加锁)。
上面的小鸡就代表worker进程,谷粒代表高并发的请求,虽然比喻有些粗糙,但也能够说明问题。
所以,在高并发场景下,关闭惊群锁,每个worker都把所有的监听套接字加入到自己的epoll中去,让它们都试图去accept新的请求,这样做能够提升处理请求的效率。
而且,从高版本的Nginx开始,惊群锁也默认置为了关闭状态。
官方对此作了压力测试的对比,具体可见如下:https://www.nginx.com/blog/socket-sharding-nginx-release-1-9-1/
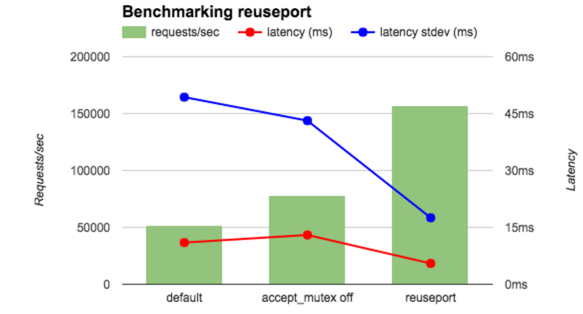
(先忽略reuseport,比对default和accept_mutux off的两种情况)
模型三
在Nginx1.9.1版本中,引入了新的socket网络选项,SO_REUSEPORT.
首先解释下这个选项:当socket设置了这个选项,可以让多个设置了这个选项的socket绑定和监听同一个端口(准确滴说是一个ip:port对)
1 default时候的网络模型:
在原始模型中,所有的worker通过master的fork调用,都公用一个socket来监听80端口(或其它端口)
如果开启SO_REUSEPORT特性,如下:
1 | server { |
则master在解析配置文件的时候创建监听套接字会有不同的动作:
它会按照worker的数目 n,对于每个ip:port对,都会克隆出多个监听socket,如下:(以4个worker为例)
可以看到,对于同一个端口,master建立了4个监听套接字,这四个监听套接字都bind到80端口。(需要注意的是,如果套接字不设置SO_REUSEPORT属性,那么当多个套接字bind到同一个端口时,会报错失败。当然这里每个套接字都设置了SO_REUSEPORT属性)
然后经过fork出worker进程:
然后,每个worker会根据自己的ID顺序号,将“属于自己”的监听套接字加入到自己的epoll中。(这段是翻看源码才能获知的,一开始怎么都想不明白~~)
以监听80端口的那四个套接字来说,worker1进程只会把套接字1加入自己的epoll中。如下图所示:
这样,每个worker都再也不用去抢监听锁讲监听套接字加入自己的epoll系统中了,现在每个worker的epoll中始终都有着属于自己的监听套接字。可以对比一下:
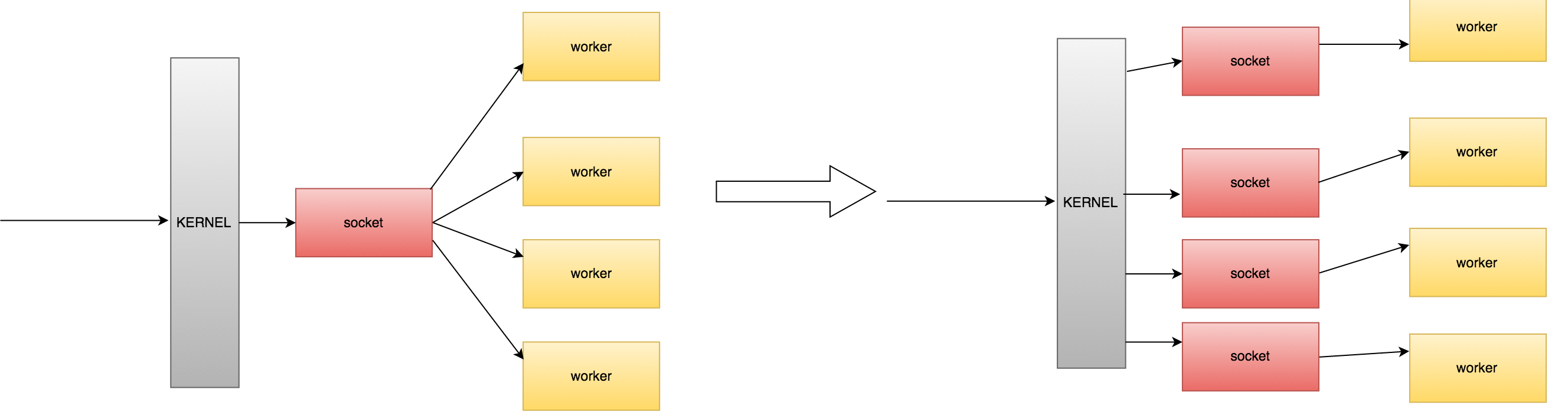
注意:在这种模式下,若某个端口有请求到来,是内核来决定将请求分发到那个监听套接字上,而且这种分发一般都是较为均衡的。
再来比对一下官方的测试数据:
其QPS和平均延时以及延时标准差都明显降低了。
总结
1 第一种默认的抢锁模式:
在大多数请求量适中的环境中都表现很优秀,而且从Nginx内部做到了解决惊群问题,具有跨平台的优势。而且由于解决了惊群问题,极大降低了CPU的负荷。
2 第二种“惊群”模式:
在第二种模式下,Nginx任由“惊群”现象的产生,让每个worker都尽自己的力量去抢到更多的请求。第二种模式在高并发场景下非常有效,但由于每次请求都会让所有worker去争抢请求,必然增大了CPU的负荷。
3 第三种reuseport模式:
在这种情况下,每个worker都有”专属于“自己的监听套接字,不用去挣抢锁,完全由内核将请求分发到各个套接字上面,做到了高效且降低CPU的负荷的特定。
下面是官方的对比:
